En este capitulo veremos algunas alternativas para realizar transformaciones utilizando R. Utilizaremos de distintas sintanxis de programación mediante el uso de paquetes y R base.
7 Algunos paquetes sugeridos
A cotinuación veremos el uso de dos paquetes recomendados para análisis de datos ‘Tidyverse’ y ‘data.table’
7.1 Tidyverse
Este es un “paquete de paquetes” que permite cargar una serie de herramientas útiles para el tratamiento de datos. Para profundizar sobre los usos de este paquete se recomienda la lectura de R for Data science.
Es un paquete que puede facilitar el uso inicial de R porque la sintaxis en inglés de compone de funciones como: ‘mutate’ que sirve para crear o editar columnas ( mutar la tabla de datos ), ‘arrange’ que sirve para ordenar, ‘group_by’ para agrupar por categorias y así. Estos ejemplos corresponden a funciones del paquete ‘dplyr’ que se puede cargar de forma individual o con ‘tidyverse’.
7.1.1 Comenzaremos conociendo funciones del paquete ‘dplyr’
Características principales:
Enfoque en verbos: dplyr se basa en verbos que describen acciones comunes en la manipulación de datos, como filtrar, seleccionar, ordenar, etc. Esto hace que el código sea más legible y fácil de entender.
Sintaxis “pipe” (%>% o |>): Permite encadenar múltiples operaciones de forma secuencial, lo que facilita la lectura y la escritura del código.
Integración con tidyverse: dplyr funciona a la perfección con otros paquetes del tidyverse, como ggplot2 para visualización y tidyr para la limpieza de datos.
Funciones principales:
7.1.2 filter
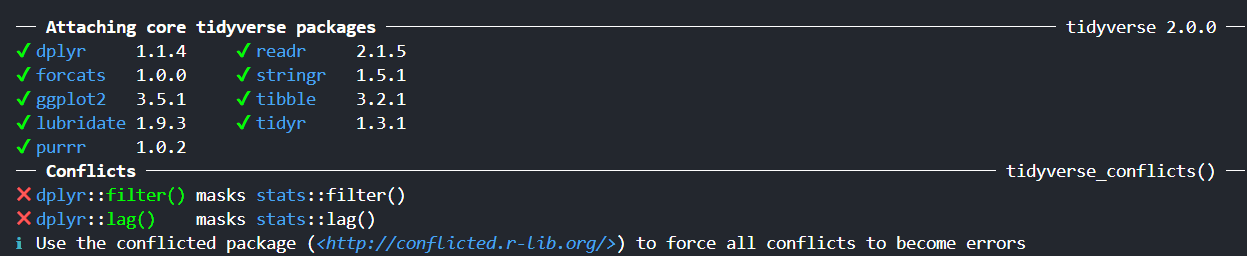
Cundo cargas el paquete tidyverse aparece un print de pantalla como el siguiente:
Esto nos indica una alerta de conflicto: ‘filter()’ entra en conflicto con la función ‘stats::filter()’ del paquete stats. Esto se debe a que ambas funciones tienen el mismo nombre, ‘stats’ es un paquete que se carga automáticamente con R base.
¿Cómo resolverlo?
Si necesitas usar la función ‘filter()’ de stats, puedes llamarla explícitamente usando ‘stats::filter()’. Si cargas dplyr después de stats, la función ‘filter()’ de dplyr tendrá prioridad. Si consideramos que por lo general ‘dplyr’ o ‘tidyverse’ serán cargados luego de abrir ‘R’, por lo general se cargará posteriormente la función de ‘dplyr’.
Ahora veamos un ejemplo del uso de la función con la tabla mtcars que viene cargada en R.
# Primero cargamos la librería tidyverselibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
# Filtrar los coches con 4 cilindrosdplyr::filter(mtcars, cyl ==4)
Como ves las funciones anteriores no utilizan la ‘pipe’ ( %>% o |>) una alternativa para trabajar con la pipe haciendo lo mismo anterior corresponde a:
# Filtrar los coches con 4 cilindrosmtcars %>% dplyr::filter(cyl ==4)
En los ajemplos anteriores se imprimen todas las filas de filtradas. Como la tabla es corta no resulta problemático, pero con una tabla más grande puede ser poco útil, en ese caso es posible agregar la función ‘head()’
mtcars %>% dplyr::filter(hp >100& am ==0) %>%head(n =10)
Permite extraer una columna o valor como un vector de datos.
# Extraer la columna "hp" como un vectorhp_vector <-pull(mtcars, hp)
7.1.13 across
Es una función que ayuda a aplicar una función a múltiples columnas.
# Calcular la media de todas las columnas numéricas, usando 'where' y la función 'is.numeric' sin parentesis.mtcars %>%summarise(across(where(is.numeric), mean))
mpg cyl disp hp drat wt qsec vs am gear carb
1 20.09 6.188 230.7 146.7 3.597 3.217 17.85 0.4375 0.4062 3.688 2.812
7.1.14 case_when
Esta función permite crear nuevas columnas basadas en condiciones, permite recodificar variables. Se puede combinar con el uso de ‘mutate’
# Crear una columna "categoria_hp" que clasifica los coches según su potenciamtcars %>%mutate(categoria_hp =case_when( hp <100~"Baja", hp >=100& hp <200~"Media", hp >=200~"Alta" ))
Esta función es similar a ‘case_when’ solo que sirve para dos condicionales, a menos que se aniden varios ‘if_else’, pero eso puede ser menos legible que la sintaxis de ‘case_when’.
# Crear una columna "potente" que indica si el coche tiene más de 150 caballos de fuerzamtcars %>%mutate(potente =if_else(hp >150, TRUE, FALSE))
Existen diversas funciones de ‘dplyr’ que permiten ‘fusionar’ bases de datos o planillas, segun sus variables. Estas funciones se puyede agrupar en una familia de ‘join’ dependiendo del uso especifico que queramos podemos utilizar un ’_join’ adecuado.
Como ejemplo del diagrama anterior podemos tomar el caso de ‘left_join’ al realizar este dipo de unión lo que hacemos es que aquellos elementos del objeto ‘y’ que coinciden con alguno de ‘x’ quedarán en el conjunto, podemos pensar en esto como una variable llemada x, que tiene valores semejantes en y, entonces al hacer ‘left_join’ de x con y, la tabla se quedará con los datos de x más aquellos de y que coincidan.
Si la columna que se usa para unir las tablas tiene diferente nombre en cada data frame, puedes especificar los nombres en el argumento by: by = c(“columna_df1” = “columna_df2”).
Para ver un ejemplo sencillo utilizaremos dos data.frame o tablas, creadas para estos efectos. df1 y df2
ID nombre edad calificacion
1 1 Ana 20 85
2 2 Juan 22 90
3 3 Pedro 21 NA
4 4 Maria 23 NA
Conserva todas las filas de df1 (la izquierda).
Agrega las columnas de df2 que coinciden con df1 según la columna “ID”.
Si no hay coincidencia en df2, las nuevas columnas tendrán valores NA.
Ahora uno por la derecha
right_join(df1, df2, by ="ID")
ID nombre edad calificacion
1 1 Ana 20 85
2 2 Juan 22 90
3 5 <NA> NA 78
Conserva todas las filas de df2 (la derecha).
Agrega las columnas de df1 que coinciden con df2 según la columna “ID”.
Si no hay coincidencia en df1, las nuevas columnas tendrán valores NA.
Un cruce que mantiene solo lo que está a la izquierda y derecha.
inner_join(df1, df2, by ="ID")
ID nombre edad calificacion
1 1 Ana 20 85
2 2 Juan 22 90
Conserva solo las filas donde hay coincidencia en ambas tablas según la columna “ID”.
Un cruce que conserva todas las filas de ambas tablas
full_join(df1, df2, by ="ID")
ID nombre edad calificacion
1 1 Ana 20 85
2 2 Juan 22 90
3 3 Pedro 21 NA
4 4 Maria 23 NA
5 5 <NA> NA 78
Conserva todas las filas de ambas tablas.
Si no hay coincidencia, las columnas de la otra tabla tendrán valores NA.
El anti_join devuelve las filas de la primera tabla (df1 en este caso) que no tienen coincidencias en la segunda tabla (df2) según la columna especificada en by (en este caso, “ID”).
anti_join(df1, df2, by ="ID")
ID nombre edad
1 3 Pedro 21
2 4 Maria 23
Esta función es útil para:
Identificar las filas que faltan en una tabla con respecto a otra.
Filtrar las filas de una tabla que no se encuentran en otra.
Encontrar valores únicos en una tabla que no están presentes en otra.