7Guía de Transición de SPSS a R para Análisis Estadístico
Esta guía se nutre de diversas fuentes. Incorpora una parte conceptual y también código. Las referencias se numera en corchetes, por ejemplo: [1] corresponde a la primera referencia indicada al final del capitulo, por ello los numeros harán referencia a documentos a lo largo del capitulo y no necesariamente se presentan de forma correlativa.
7.1 1. Introducción: SPSS vs. R en el Panorama Actual del Análisis de Datos
IBM SPSS Statistics es un software de pago para análisis estadístico, especialmente en las ciencias sociales, la investigación de mercados y la salud. Posee una interfaz gráfica de usuario/usuaria (GUI) intuitiva y sus procedimientos estandarizados.[1] Permite a las personas usuarias realizar análisis complejos mediante menús desplegables y cuadros de diálogo, con la opción de utilizar sintaxis para la automatización.
Por otro lado, R es un lenguaje de programación y un entorno de software libre diseñado específicamente para la computación estadística y la creación de gráficos.[3] Es un proyecto de código abierto mantenido por una vasta y activa comunidad global de académicos, estadísticos y científicos de datos.[3] Esta naturaleza abierta significa que R evoluciona rápidamente, con nuevos paquetes y funcionalidades que a menudo están disponibles años antes que en software propietario como SPSS.[5]
El propósito de este capítulo es servir como una guía detallada para usuarias con experiencia en SPSS que deseen aprender a utilizar R para el análisis estadístico. Se busca facilitar esta transición comparando los flujos de trabajo, explicando las diferencias conceptuales y destacando las ventajas de R, al tiempo que se abordan los desafíos comunes. Se cubrirán desde las tareas más básicas, como la importación de datos y la manipulación de variables, hasta análisis estadísticos intermedios, como pruebas t, ANOVA, chi-cuadrado, correlaciones y regresión lineal, estableciendo paralelos directos con los procedimientos equivalentes en SPSS.
7.2 Diferencias Conceptuales y Filosóficas Clave
Comprender las diferencias fundamentales en la filosofía y el diseño entre SPSS y R es crucial para una transición exitosa.
Interfaz y Flujo de Trabajo: SPSS está fundamentalmente orientado a una interfaz gráfica (GUI). Las operaciones se realizan principalmente a través de menús y cuadros de diálogo, aunque ofrece un lenguaje de sintaxis para la automatización y la reproducibilidad.[2] R, en cambio, es primordialmente un lenguaje de programación basado en líneas de comando.[3] Aunque existen GUIs para R (como RStudio, que se discutirá más adelante), el flujo de trabajo principal implica escribir y ejecutar scripts.[8] Esto puede parecer intimidante al principio, pero ofrece un control mucho mayor y una reproducibilidad inherente.[5]
Costo y Licencia: R es un software de código abierto y completamente gratuito.[4] SPSS es un software comercial propiedad de IBM que requiere la compra de licencias, cuyo costo puede ser significativo, especialmente para usuarias individuales o instituciones pequeñas.[6]
Manejo de Datos y Objetos: SPSS opera principalmente sobre un único conjunto de datos activo a la vez, presentado en una vista similar a una hoja de cálculo.[7] R es un lenguaje orientado a objetos. Los datos, resultados de análisis, funciones, etc., se almacenan como objetos en la memoria del entorno de trabajo.[8] Esto permite una gran flexibilidad para manipular múltiples conjuntos de datos y extraer resultados específicos de los análisis para usarlos en pasos posteriores.[5] R maneja diversas estructuras de datos (vectores, matrices, data frames, listas) de forma nativa, lo que puede ser un desafío inicial pero ofrece una potencia considerable.[11]
Salida de Resultados: SPSS genera resultados en una ventana de visor separada, con tablas y gráficos preformateados que pueden copiarse y pegarse fácilmente en informes.[2] La salida de R en la consola es a menudo menos formateada por defecto.[11] Sin embargo, los resultados de los análisis en R son objetos que pueden ser consultados y manipulados programáticamente.[8] Además, herramientas como R Markdown o Quarto permiten integrar código R, texto narrativo y resultados (tablas, gráficos) en documentos dinámicos y reproducibles de alta calidad, superando el flujo de trabajo de copiar y pegar de SPSS.[5]
Flexibilidad y Extensibilidad: La fortaleza central de R radica en su flexibilidad y extensibilidad a través de miles de paquetes contribuidos por la comunidad.[6] Estos paquetes cubren una gama mucho más amplia de métodos estadísticos, técnicas de aprendizaje automático y capacidades gráficas que las disponibles en SPSS estándar.[5] Si existe una nueva técnica estadística, es muy probable que se implemente primero en R.[5] SPSS, aunque potente para análisis estándar, es menos flexible para métodos no convencionales o personalizaciones muy específicas.[5]
Estas diferencias implican que la transición de SPSS a R no es simplemente aprender una nueva sintaxis, sino adoptar un paradigma diferente para el análisis de datos, uno que prioriza la codificación, la reproducibilidad y la flexibilidad.
7.3 Primeros Pasos con R y RStudio
Para comenzar a trabajar con R, se necesitan dos componentes principales: el propio lenguaje R y un Entorno de Desarrollo Integrado (IDE) como RStudio.
Instalación:
R: Descargue e instale la versión base de R adecuada para su sistema operativo (Windows, macOS, Linux) desde el Comprehensive R Archive Network (CRAN).[3] Este es el motor subyacente que ejecuta el código.
RStudio: Descargue e instale RStudio Desktop (la versión gratuita es suficiente) desde el sitio web de Posit (anteriormente RStudio).[3] RStudio es una interfaz gráfica que facilita enormemente el trabajo con R. Si conoce otro editor de codigo, como VSCoidum o VSCode también puede utilizarlo para trabajar con R.
La Interfaz de RStudio: RStudio proporciona un entorno organizado que integra varias herramientas esenciales, generalmente en cuatro paneles o cuadrantes [8]:
Editor de Scripts/Visor de Datos (Superior Izquierda): Aquí es donde se escriben y guardan los scripts de R (archivos .R). También se pueden visualizar conjuntos de datos en un formato de hoja de cálculo haciendo clic en ellos en el panel del Entorno.
Consola R (Inferior Izquierda o Derecha): Aquí es donde se ejecuta el código R interactivamente y donde se muestra la salida de texto. Se puede escribir código directamente aquí o ejecutar líneas/secciones desde el editor de scripts.
Entorno/Historial (Superior Derecha): La pestaña “Environment” muestra todos los objetos (conjuntos de datos, variables, funciones) actualmente cargados en la memoria de R. La pestaña “History” registra los comandos ejecutados.
Archivos/Gráficos/Paquetes/Ayuda/Visor (Inferior Derecha): Este panel multifuncional permite explorar archivos, ver los gráficos generados, administrar los paquetes instalados, acceder a la documentación de ayuda de R y visualizar contenido web o informes R Markdown.
Concepto de Paquetes: La funcionalidad base de R se amplía enormemente mediante paquetes (packages). Estos son colecciones de funciones, datos y documentación desarrollados por la comunidad R.[6] Para usar un paquete, primero debe instalarse (una sola vez) y luego cargarse en cada sesión de R donde se necesite [18]:
install.packages(“nombre_del_paquete”): Descarga e instala un paquete desde CRAN. Por ejemplo, install.packages(“tidyverse”) instala un conjunto fundamental de paquetes para la ciencia de datos.[18]
library(nombre_del_paquete): Carga un paquete instalado en la sesión actual, haciendo sus funciones disponibles. Por ejemplo, library(tidyverse).[18]
Familiarizarse con RStudio y el concepto de paquetes es el primer paso esencial para cualquier persona usuaria que provenga de SPSS.[8]
7.4 Importación y Exportación de Datos: SPSS vs. R
Una de las primeras tareas en cualquier análisis es cargar los datos. Tanto SPSS como R pueden manejar diversos formatos de archivo, pero sus enfoques difieren.
7.4.1 Importación de Archivos .sav (SPSS):
SPSS: Se utiliza el menú Archivo > Abrir > Datos… y se selecciona el archivo .sav.[22] Es directo y maneja automáticamente las características de los archivos SPSS (etiquetas de valor, valores perdidos definidos por la persona usuaria).
R: El paquete haven es la herramienta estándar de oro para leer archivos de SPSS (y también de Stata y SAS).[21] La función principal es haven::read_sav().
Manejo de etiquetas: read_sav preserva las etiquetas de variable y valor como atributos en R. Las etiquetas de valor se pueden convertir en factores de R usando haven::as_factor().[21]
Valores perdidos: El argumento user_na = TRUE preserva los valores perdidos definidos por la persona usuaria de SPSS como objetos especiales labelled_spss, mientras que user_na = FALSE (el valor predeterminado) los convierte en NA estándar de R.[24]
Otros paquetes como foreign (read.spss) existen pero haven (parte del tidyverse) es generalmente preferido por su mejor manejo de las características modernas de los archivos y su integración con tidyverse.[26] El paquete misty también usa haven internamente (misty::read.sav).[23]
7.4.2 Importación de Archivos .csv (Valores Separados por Comas):
SPSS: Se utiliza Archivo > Abrir > Datos…, se cambia el tipo de archivo a CSV (*.csv) y se sigue el Asistente de Importación de Texto para especificar delimitadores, si la primera fila contiene nombres de variables, etc..[22]
R: El paquete readr (parte del tidyverse) proporciona readr::read_csv().
Ventajas sobre base::read.csv(): read_csv es significativamente más rápido, muestra una barra de progreso, produce tibbles (una versión moderna de data frames que evita problemas comunes como la conversión automática de cadenas a factores), y es más reproducible entre sistemas operativos.[25]
Manejo de tipos de columna: read_csv adivina los tipos de columna leyendo las primeras 1000 filas, pero es recomendable especificar los tipos explícitamente usando el argumento col_types para mayor robustez y reproducibilidad.[25]
7.4.3 Importación de Archivos .xlsx (Excel):
SPSS: Se utiliza Archivo > Abrir > Datos…, se selecciona el tipo de archivo Excel (.xls, .xlsx, *.xlsm) y se elige la hoja de cálculo específica a importar y si la primera fila contiene nombres de variables.[22]
R: El paquete readxl (también parte del tidyverse) proporciona readxl::read_excel(). Sintaxis básica: library(readxl); mi_data <- read_excel(“ruta/a/mi_archivo.xlsx”, sheet = “NombreHoja”).[28]
Especificar hoja: Se puede especificar la hoja por número (p.ej., sheet = 1) o por nombre (p.ej., sheet = “Resultados”).[28] La función excel_sheets() lista los nombres de las hojas disponibles.[28]
Ventajas: readxl no tiene dependencias externas (como Java), maneja formatos .xls y .xlsx, y se integra bien con el tidyverse.[28]
7.4.4 Exportación de Datos:
SPSS: Se utiliza Archivo > Guardar como… para guardar en formato .sav o se exporta a otros formatos. La sintaxis usa SAVE OUTFILE.
R: A SPSS (.sav): haven::write_sav(mi_data_frame, “nuevo_archivo.sav”).[21]}
A CSV: readr::write_csv(mi_data_frame, “nuevo_archivo.csv”).
A Excel: El paquete writexl proporciona writexl::write_xlsx(mi_data_frame, “nuevo_archivo.xlsx”).
Nota: El paquete foreign tiene write.foreign, pero puede tener limitaciones con archivos SPSS modernos (p.ej., más de 255 variables, manejo de cadenas).[29] haven es la opción recomendada para exportar a SPSS.
Mientras que SPSS ofrece un asistente de importación más unificado a través de sus menús, R se basa en paquetes especializados (haven, readr, readxl) que proporcionan funciones optimizadas y flexibles para cada tipo de archivo. Comprender los argumentos clave de estas funciones de R (como user_na en read_sav, col_types en read_csv, o sheet en read_excel) es fundamental para asegurar que los datos se importen correctamente, preservando la información relevante como etiquetas o manejando adecuadamente los valores perdidos. Esta especificidad de funciones en R contrasta con el enfoque más generalista del asistente de SPSS, ofreciendo mayor control a costa de requerir un conocimiento más explícito de la función a utilizar.
7.5 Manipulación de Datos: Comparativa de Flujos de Trabajo
La manipulación de datos (preparación, limpieza, transformación) es una parte fundamental del análisis. SPSS y R (dplyr) abordan estas tareas de maneras distintas.
7.5.1 Enfoque General:
SPSS: Utiliza principalmente menús interactivos (p.ej., Transformar, Datos) que guían a la persona usuaria a través de cuadros de diálogo para realizar operaciones como recodificar variables, calcular nuevas variables, seleccionar casos o fusionar archivos.[31] La sintaxis correspondiente se puede generar y guardar.
R (dplyr): Se basa en un conjunto de “verbos” consistentes y funciones que se aplican directamente a los data frames mediante código.[20] El paquete dplyr, parte del tidyverse, es el estándar de facto para la manipulación de datos en R.[34]
7.5.2 Creación y Recodificación de Variables:
SPSS:
Recodificar: Transformar > Recodificar en distintas variables… (o …en las mismas variables). Permite definir mapeos de valores antiguos a nuevos, rangos, y manejar valores perdidos a través de cuadros de diálogo.[31] Ejemplo: Agrupar edades en categorías.
Calcular: Transformar > Calcular variable…. Permite crear nuevas variables usando expresiones matemáticas o funciones aplicadas a variables existentes.[37]
R (dplyr):
mutate(): Crea nuevas variables o modifica existentes.20 Se combina frecuentemente con:
case_when(): Para lógica condicional compleja (equivalente a múltiples IF en SPSS).20 Ejemplo:
SPSS: Datos > Seleccionar casos…. Permite seleccionar subconjuntos basados en condiciones lógicas (Si se satisface la condición), rangos, filtros aleatorios, etc. Los casos no seleccionados pueden filtrarse (tacharse) o eliminarse.[32] Ejemplo: Seleccionar solo mujeres (genero = 2).
R (dplyr):
filter(): Mantiene las filas que cumplen una o más condiciones lógicas.20 Condiciones: Se usan operadores lógicos estándar (==, !=, >, <, >=, <=, & (y), | (o), ! (no), %in%).[18] Ejemplo:
SPSS: Generalmente, las variables se seleccionan dentro de los cuadros de diálogo de los procedimientos específicos. Para crear un subconjunto de variables en un nuevo archivo, se puede usar Guardar como… y especificar las variables a mantener/eliminar, o usar Datos > Copiar conjunto de datos. La sintaxis KEEP o DROP también se puede usar.33
R (dplyr):
select(): Selecciona columnas por nombre, posición o usando funciones auxiliares (starts_with(), ends_with(), contains(), everything()).20 Permite renombrar columnas dentro de la misma función.20
7.5.5 Fusión de Conjuntos de Datos (Unión por Clave):
SPSS: Datos > Fusionar archivos > Añadir variables…. Requiere que ambos conjuntos de datos estén ordenados por la(s) variable(s) clave. Se especifica el archivo externo y la(s) variable(s) clave.33
R (dplyr):
Funciones *_join(): left_join(), right_join(), inner_join(), full_join(). Especifican los data frames a unir y la(s) variable(s) clave mediante el argumento by.20 No requiere ordenación previa. Ejemplo: left_join(datos_demograficos, datos_respuestas, by = “ID_participante”).[20]
El enfoque de dplyr en R, con sus verbos consistentes y la capacidad de encadenar operaciones usando el operador “pipe” (%>%), fomenta un código más legible y reproducible en comparación con la navegación por menús de SPSS o incluso su sintaxis a veces verbosa. Mientras que SPSS ofrece una experiencia visual e interactiva para la manipulación, R (dplyr) proporciona un marco programático poderoso que define una “gramática de manipulación de datos”, donde operaciones complejas se pueden construir combinando verbos simples de manera lógica y secuencial.[20] Esta diferencia es fundamental: SPSS guía a la persona usuaria a través de pasos discretos, mientras que R permite construir un flujo de manipulación continuo y documentado en código.
7.5.6 Tabla: Mapeo de Tareas Comunes de Manipulación de Datos: SPSS vs. R (dplyr)
group_by(region) %>% summarise(media_ventas = mean(ventas), n = n())
Fusionar (Añadir Vars)
Datos > Fusionar archivos > Añadir vars…
left_join(), inner_join(), etc.
left_join(df1, df2, by = “ID_comun”)
Fusionar (Añadir Casos)
Datos > Fusionar archivos > Añadir casos…
bind_rows()
bind_rows(df_enero, df_febrero)
7.6 Estadísticas Descriptivas y Gráficos Básicos
Obtener resúmenes numéricos y visualizaciones iniciales de los datos es un paso esencial antes de realizar análisis inferenciales más complejos.
7.6.1 Procedimientos Descriptivos en SPSS: SPSS ofrece varias rutas para obtener estadísticas descriptivas, cada una con sus fortalezas:
Frequencies (Frecuencias): Ideal para variables categóricas (nominales/ordinales), proporciona tablas de frecuencias, porcentajes (incluyendo válidos y acumulados) y el modo.[2] También puede generar gráficos de barras o circulares.[44] Para variables continuas (escala), puede calcular percentiles, cuartiles, media, mediana, desviación estándar, mínimo, máximo, y generar histogramas.[46] Menú: Analizar > Estadísticos Descriptivos > Frecuencias….[44]
Descriptives (Descriptivos): Optimizado para variables continuas (escala). Calcula por defecto N, mínimo, máximo, media y desviación estándar.[48] Opciones adicionales incluyen suma, varianza, rango, error estándar de la media, curtosis y asimetría.[48] Puede guardar puntuaciones Z.[48] Menú: Analizar > Estadísticos Descriptivos > Descriptivos….[48]
Explore (Explorar): Proporciona un conjunto más completo de descriptivos y gráficos para una o más variables continuas, opcionalmente divididas por los niveles de una variable categórica.[2] Incluye descriptivos estándar, percentiles, valores atípicos, pruebas de normalidad (Kolmogorov-Smirnov, Shapiro-Wilk) y gráficos como diagramas de caja (boxplots), histogramas y gráficos de normalidad (Q-Q plots).[2] Menú: Analizar > Estadísticos Descriptivos > Explorar….[47]
Compare Means (Comparar Medias) > Means: Calcula estadísticas descriptivas (media, N, desviación estándar por defecto; muchas otras opcionales) para una variable dependiente continua, desglosadas por las categorías de una o más variables independientes (factores).[2] Menú: Analizar > Comparar Medias > Medias….[51]
Crosstabs (Tablas de Contingencia): Utilizado principalmente para examinar la relación entre dos o más variables categóricas, mostrando recuentos conjuntos.2 Puede incluir porcentajes por fila, columna o total.[52] Menú: Analizar > Estadísticos Descriptivos > Tablas de contingencia….[47]
7.6.2 Estadísticas Descriptivas en R:
Funciones Base: R base proporciona funciones individuales para estadísticas específicas: mean(), median(), sd(), var(), min(), max(), range(), quantile(), summary() (proporciona mínimo, 1er cuartil, mediana, media, 3er cuartil, máximo para variables numéricas, y frecuencias para factores), table() (para tablas de frecuencia de una o más variables categóricas).[12]
Paquete dplyr: La función summarise() (o summarize()) se usa para calcular múltiples estadísticas descriptivas, a menudo en combinación con group_by() para obtener resúmenes por grupo.18 Ejemplo: datos %>% group_by(Categoria) %>% summarise(Media_Valor = mean(Valor, na.rm = TRUE), SD_Valor = sd(Valor, na.rm = TRUE), N = n()). El argumento na.rm = TRUE es crucial para excluir valores perdidos en los cálculos.
Otros Paquetes: Paquetes como psych (describe(), describeBy()) o skimr (skim()) ofrecen resúmenes descriptivos más detallados y formateados.
7.6.3 Introducción a la Creación de Gráficos en R: Base R vs. ggplot2:
Gráficos Base R: Funciones como plot() (genérica, crea scatterplots por defecto), hist(), boxplot(), barplot() permiten crear gráficos rápidamente con sintaxis concisa.[12] Son útiles para exploración rápida. Sin embargo, la personalización avanzada puede volverse compleja y menos intuitiva.
ggplot2: Parte del tidyverse, ggplot2 implementa la “Gramática de Gráficos”.[56] Este enfoque conceptual permite construir gráficos capa por capa, combinando datos, mapeos estéticos (cómo las variables se representan visualmente: posición, color, tamaño, forma), y objetos geométricos (puntos, líneas, barras, etc.).56 Aunque la sintaxis inicial puede ser más larga que la de base R, ggplot2 ofrece una flexibilidad y potencia enormes para crear visualizaciones complejas, personalizadas y de calidad para publicación.[5] El operador + se usa para añadir capas (geoms, escalas, etiquetas, temas, etc.) al gráfico base creado con ggplot().[56]
Creación de Gráficos Básicos:
SPSS: Se utiliza el Generador de gráficos (Graphs > Chart Builder) o los Cuadros de diálogo antiguos (Graphs > Legacy Dialogs). Muchos procedimientos (como Frequencies o Explore) también incluyen opciones para generar gráficos relevantes directamente.[2]
R (Histograma):
Base R:hist(datos$variable_continua)
ggplot2:ggplot(datos, aes(x = variable_continua)) + geom_histogram(binwidth = 5) .[56] binwidth controla el ancho de las barras.
R (Gráfico de Barras):
Base R:barplot(table(datos$variable_categorica))
ggplot2:ggplot(datos, aes(x = variable_categorica)) + geom_bar() [56] geom_bar cuenta las frecuencias automáticamente.
R (Diagrama de Dispersión):Base R:plot(datos$variable_x, datos$variable_y)
ggplot2:ggplot(datos, aes(x = variable_x, y = variable_y)) + geom_point() .[56] Se pueden añadir estéticas como color: aes(x=var_x, y=var_y, color=grupo).
Ejemplos ggplot2:
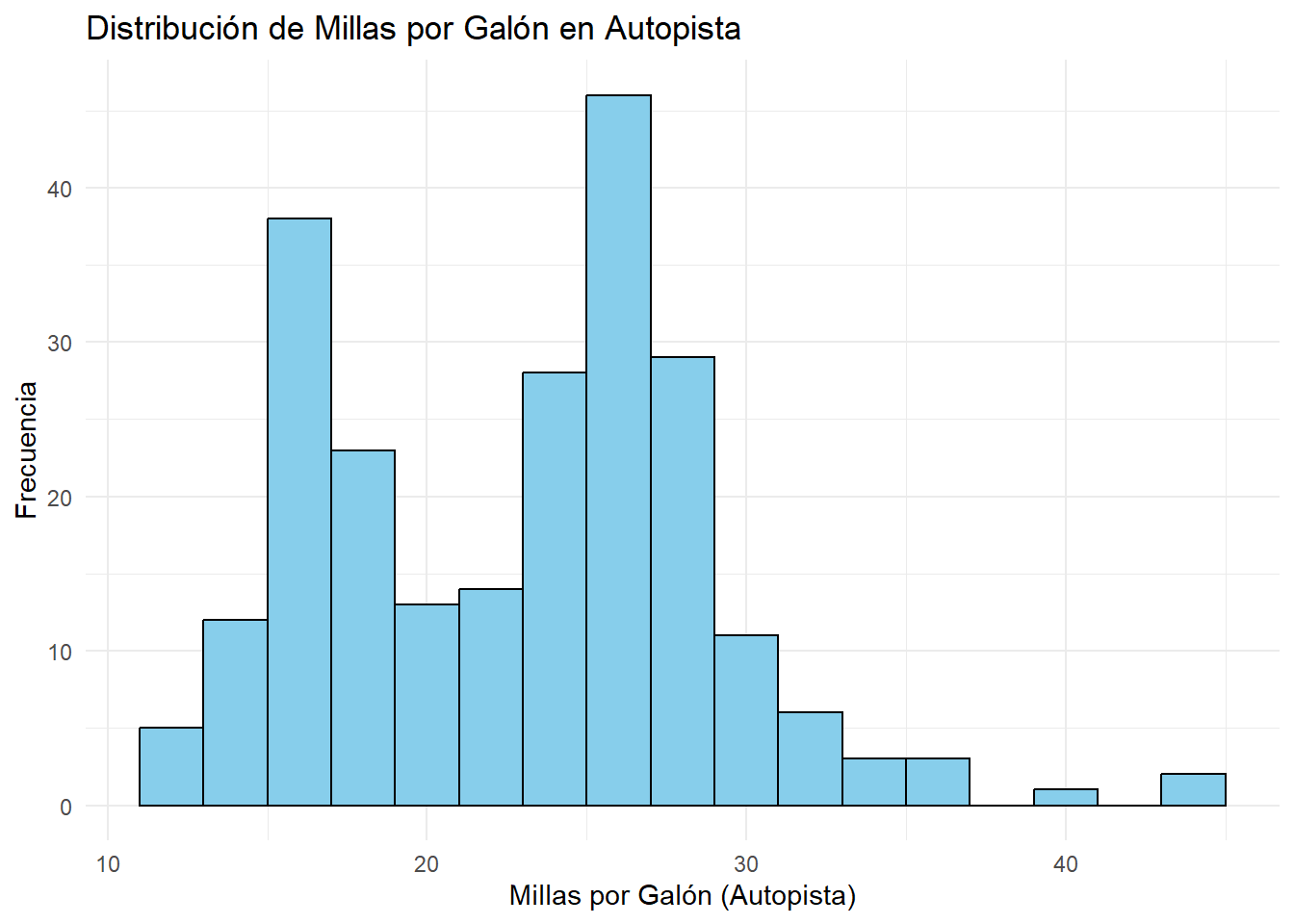
library(ggplot2)# Histograma de millas por galón en autopista (mpg dataset)ggplot(mpg, aes(x = hwy)) +geom_histogram(binwidth =2, fill ="skyblue", color ="black") +labs(title ="Distribución de Millas por Galón en Autopista", x ="Millas por Galón (Autopista)", y ="Frecuencia") +theme_minimal()
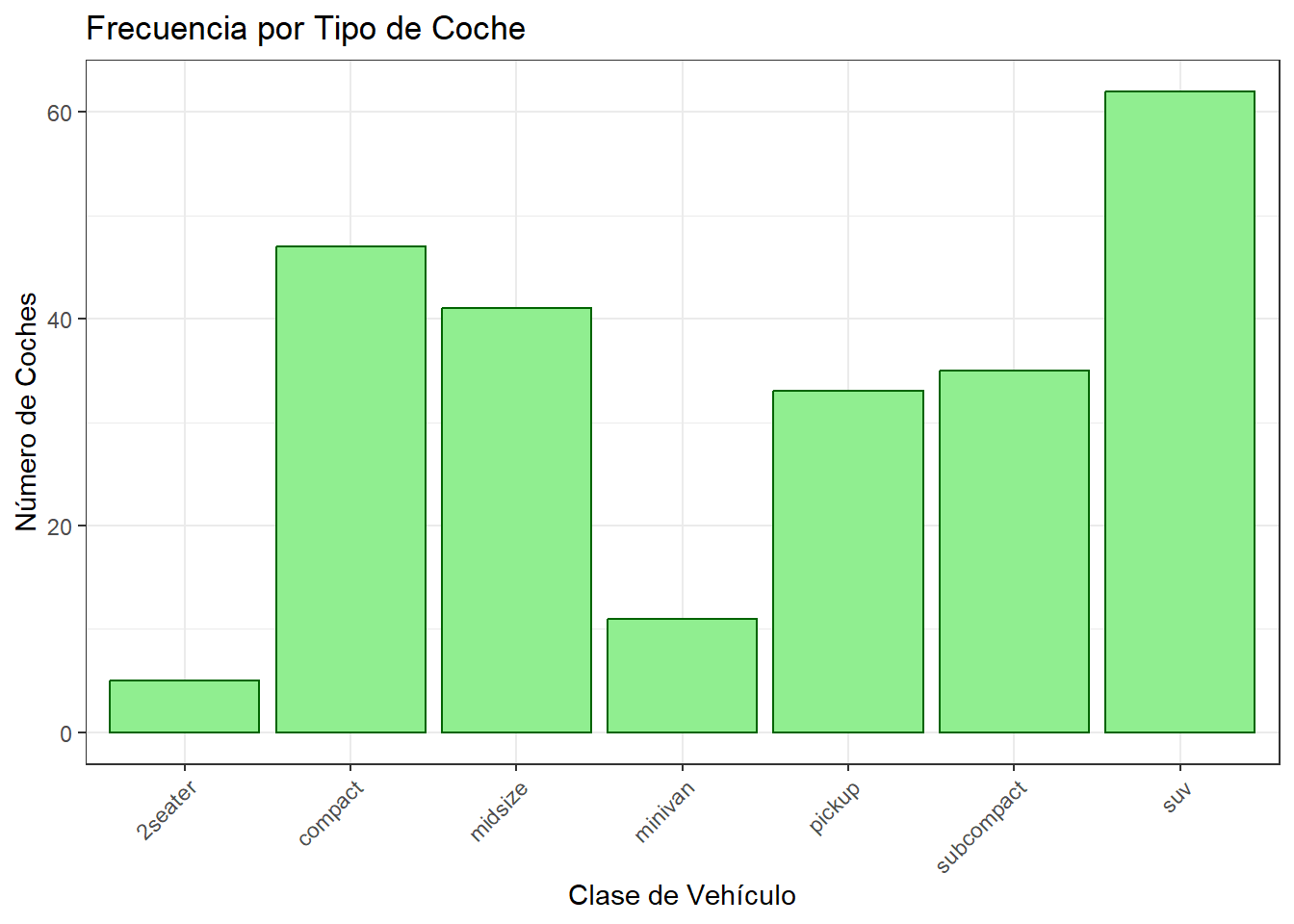
# Gráfico de barras de tipo de coche (mpg dataset)ggplot(mpg, aes(x = class)) +geom_bar(fill ="lightgreen", color ="darkgreen") +labs(title ="Frecuencia por Tipo de Coche", x ="Clase de Vehículo", y ="Número de Coches") +theme_bw() +theme(axis.text.x =element_text(angle =45, hjust =1)) # Rotar etiquetas eje x
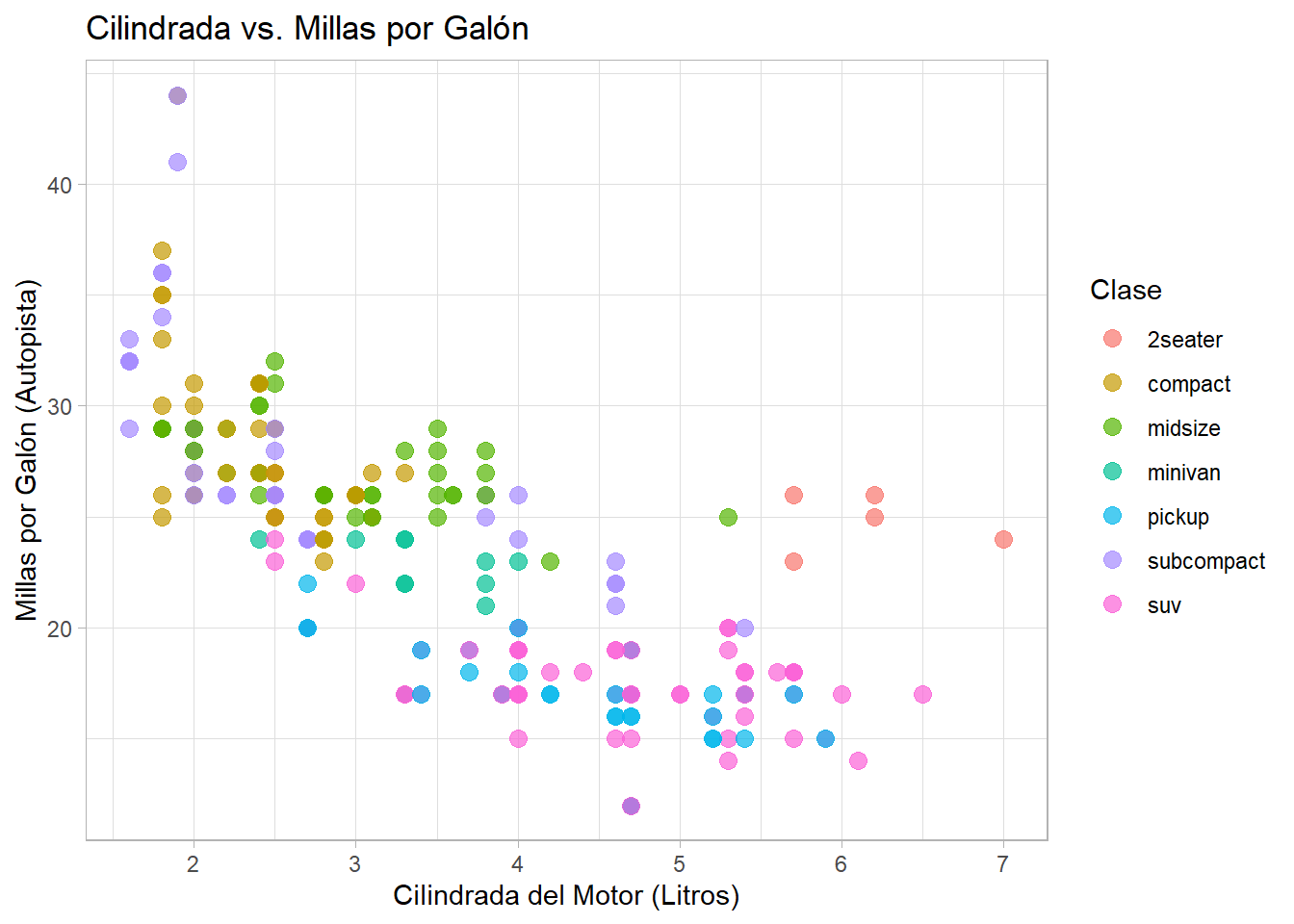
# Diagrama de dispersión: cilindrada vs millas en autopista, coloreado por tipo (mpg dataset)ggplot(mpg, aes(x = displ, y = hwy, color = class)) +geom_point(size =3, alpha =0.7) +labs(title ="Cilindrada vs. Millas por Galón", x ="Cilindrada del Motor (Litros)", y ="Millas por Galón (Autopista)", color ="Clase") +theme_light()
Una diferencia clave en el flujo de trabajo emerge aquí. En SPSS, obtener estadísticas descriptivas y crear gráficos son a menudo pasos separados o sub-opciones dentro de un procedimiento. En R, especialmente con el tidyverse, la manipulación de datos (dplyr), el resumen (dplyr::summarise) y la visualización (ggplot2) están diseñados para integrarse fluidamente. Es común usar el operador pipe (%>%) para filtrar datos, luego agruparlos, calcular estadísticas de resumen por grupo, y finalmente pasar esos resúmenes directamente a ggplot() para visualizarlos, todo en una única cadena de comandos legible. Por ejemplo: datos %>% filter(Año == 2023) %>% group_by(Region) %>% summarise(Ventas_Promedio = mean(Ventas)) %>% ggplot(aes(x = Region, y = Ventas_Promedio)) + geom_col(). Esta integración de análisis y visualización es una característica poderosa y eficiente del ecosistema R/tidyverse que difiere notablemente del enfoque más compartimentado de SPSS.
7.6.4 Tabla: Mapeo de Procedimientos Descriptivos Comunes: SPSS vs. R
Tarea/Estadística
SPSS Procedimiento(s)
R Función(es) Base
R Función(es) tidyverse (dplyr/ggplot2)
Frecuencias, Porcentajes (Categ)
Frequencies
table(), prop.table()
count(), summarise(n=n()) (+ mutate para %)
Modo (Categ)
Frequencies
(Requiere función custom)
(Requiere sumarización o paquete externo)
Media, Mediana, SD, Min, Max
Frequencies, Descriptives, Explore
mean(), median(), sd(), min(), max(), summary()
summarise() (con mean(), median(), sd(), etc.)
Percentiles/Cuartiles
Frequencies, Explore
quantile(), summary()
summarise() (con quantile())
Pruebas de Normalidad
Explore
shapiro.test()
(Usar shapiro.test() en summarise o paquete moments)
Descriptivos por Grupo
Explore, Compare Means > Means
tapply(), aggregate()
group_by() + summarise()
Tabla de Contingencia (Counts)
Crosstabs
table(), xtabs()
count() o summarise(n=n()) con 2+ group_by() vars
Histograma
Frequencies, Explore, Chart Builder
hist()
ggplot() + geom_histogram()
Gráfico de Barras
Frequencies, Chart Builder
barplot()
ggplot() + geom_bar() (para cuentas) o geom_col() (para valores pre-calculados)
Diagrama de Cajas (Boxplot)
Explore, Chart Builder
boxplot()
ggplot() + geom_boxplot()
Diagrama de Dispersión
Chart Builder, Legacy Dialogs
plot()
ggplot() + geom_point()
7.7 Estadísticas Inferenciales: Comparación de Pruebas Comunes
Realizar pruebas de hipótesis es central en el análisis estadístico. A continuación, se comparan los procedimientos para algunas de las pruebas inferenciales más comunes en SPSS y R. Para cada prueba, se indica la ruta del menú de SPSS, la función principal de R (generalmente del paquete base stats), su sintaxis básica y un ejemplo de código.
7.7.1 Prueba T para una Muestra (One-Sample T-Test):
Compara la media de una única muestra con un valor hipotético conocido.
SPSS: Analizar > Comparar medias > Prueba T para una muestra….1 Se especifica la(s) variable(s) de prueba y el valor de prueba (Test Value).
R: stats::t.test(x, mu = valor_prueba).1 x es un vector numérico que contiene los datos de la muestra. mu es el valor hipotético de la media poblacional.
Ejemplo R: t.test(datos$puntuacion_examen, mu = 70)
Interpretación R: La salida incluye el valor t, grados de libertad (df), p-valor (p.value), intervalo de confianza para la media (conf.int) y la media muestral (sample estimates).
7.7.2 Prueba T para Muestras Independientes (Independent Samples T-Test):
Compara las medias de dos grupos independientes (no relacionados).
SPSS: Analizar > Comparar medias > Prueba T para muestras independientes….1 Se especifica la(s) variable(s) de prueba (dependiente continua) y la variable de agrupación (independiente categórica con dos niveles). Se deben definir los códigos de los dos grupos.60 La salida incluye la prueba de Levene para la igualdad de varianzas, que guía si se debe usar la fila “Equal variances assumed” o “Equal variances not assumed”.[61]
R: stats::t.test(variable_dependiente ~ variable_agrupacion, data = data_frame, var.equal = FALSE).1 La interfaz de fórmula (y ~ x) es común. var.equal = FALSE (predeterminado) realiza la prueba de Welch (no asume varianzas iguales), mientras var.equal = TRUE realiza la prueba t de Student clásica (asume varianzas iguales). Ejemplo R: t.test(salario ~ genero, data = datos, var.equal = FALSE) Interpretación R: La salida (por defecto, la prueba de Welch) incluye el valor t, df, p-valor, intervalo de confianza para la diferencia de medias y las medias de cada grupo.
7.7.3 Prueba T para Muestras Relacionadas (Paired Samples T-Test):
Compara las medias de dos mediciones relacionadas en el mismo sujeto o unidad (p.ej., antes y después).
SPSS: Analizar > Comparar medias > Prueba T para muestras relacionadas….2 Se seleccionan los pares de variables a comparar.
R: stats::t.test(variable1, variable2, paired = TRUE) o usando una fórmula con datos en formato largo: t.test(resultado ~ momento_temporal, data = datos_largos, paired = TRUE).2 Ejemplo R: t.test(datos\(puntuacion_pre, datos\)puntuacion_post, paired = TRUE)
Interpretación R: La salida incluye el valor t, df, p-valor, intervalo de confianza para la diferencia media y la media de las diferencias.
7.7.4 ANOVA de un Factor (One-Way ANOVA):
Compara las medias de tres o más grupos independientes.
SPSS: Analizar > Comparar medias > ANOVA de un factor….[2] Se especifica la lista de variables dependientes y la variable factor (independiente categórica). Opciones importantes incluyen Descriptivos, Prueba de homogeneidad de varianzas (Levene) y Post Hoc (para comparaciones múltiples como Tukey, Bonferroni si el ANOVA general es significativo).[62]
R: Se usa un enfoque en dos pasos:
Ajustar el modelo: modelo_aov <- stats::aov(variable_dependiente ~ variable_factor, data = data_frame).12
Obtener la tabla ANOVA: summary(modelo_aov).12
Pruebas post-hoc: stats::TukeyHSD(modelo_aov) para comparaciones de Tukey.[62]
Verificar homogeneidad de varianzas: car::leveneTest(variable_dependiente ~ variable_factor, data = data_frame) (requiere instalar y cargar el paquete car).
Ejemplo R:
modelo_anova <-aov(rendimiento ~ tipo_fertilizante, data = datos); summary(modelo_anova); TukeyHSD(modelo_anova)
Interpretación R: summary(modelo_aov) muestra la tabla ANOVA con la fuente de variación, suma de cuadrados, df, media cuadrática, estadístico F y p-valor (Pr(>F)). TukeyHSD muestra las diferencias entre pares de grupos, sus intervalos de confianza y p-valores ajustados.
7.7.5 Prueba Chi-Cuadrado de Independencia (Chi-Square Test):
Evalúa si existe una asociación entre dos variables categóricas. SPSS: Analizar > Estadísticos Descriptivos > Tablas de contingencia….[52] Se especifica la variable de Fila y la de Columna. En el botón Estadísticos…, se marca Chi-cuadrado.[52] En Casillas…, se pueden solicitar recuentos observados, esperados y residuos.[52]
R: stats::chisq.test(table(datos\(variable1, datos\)variable2)) o usando xtabs: resultado_chisq <- chisq.test(xtabs(~ variable1 + variable2, data = datos)).[1] La función table() o xtabs() crea la tabla de contingencia necesaria.
Interpretación R: La salida incluye el valor de chi-cuadrado (X-squared), df y p-valor. Se puede acceder a los recuentos observados (resultado_chi\(observed), esperados (resultado_chi\)expected) y residuos (resultado_chi$residuals). Una advertencia puede aparecer si las frecuencias esperadas son bajas.
7.7.6 Correlación Bivariada (Pearson):
Mide la fuerza y dirección de la asociación lineal entre dos variables continuas.
SPSS: Analizar > Correlaciones > Bivariadas….[37] Se seleccionan las variables a correlacionar. Se elige el coeficiente de correlación (Pearson por defecto). Se puede especificar prueba de significación de una o dos colas.[66]
Interpretación R: cor.test devuelve el valor t, df, p-valor, intervalo de confianza para la correlación y el coeficiente de correlación muestral (cor).
7.7.7 Regresión Lineal Simple:
Modela la relación lineal entre una variable predictora (independiente) y una variable de resultado (dependiente), ambas continuas.
SPSS: Analizar > Regresión > Lineales….[2] Se especifica la variable Dependiente y la(s) Independiente(s). Opciones en Estadísticos permiten solicitar estimaciones de coeficientes, R cuadrado, tabla ANOVA. Opciones en Gráficos permiten generar gráficos de residuos para evaluar supuestos.[69]
R: Se usa un enfoque en varios pasos: Ajustar el modelo: modelo_lm <- stats::lm(variable_dependiente ~ variable_independiente, data = data_frame).12 Obtener resumen del modelo: summary(modelo_lm).12 Intervalos de confianza para coeficientes: confint(modelo_lm).
Gráficos diagnósticos: plot(modelo_lm) genera varios gráficos para evaluar supuestos.70
Ejemplo R:
modelo_reg <-lm(inscripciones ~ inversion_difusion, data = datos); summary(modelo_reg); confint(modelo_reg)
Interpretación R: summary(modelo_lm) proporciona información crucial: estimaciones de los coeficientes (intercepto y pendiente) con sus errores estándar, valores t y p-valores (Estimate, Std. Error, t value, Pr(>|t|)), R cuadrado (Multiple R-squared, Adjusted R-squared), y el estadístico F de la tabla ANOVA del modelo global con su p-valor. Una diferencia fundamental en cómo R maneja los resultados de estos análisis es su naturaleza orientada a objetos. Mientras que SPSS presenta los resultados en tablas formateadas dentro de un visor de salida estático, las funciones de R como t.test(), aov(), lm(), y chisq.test() devuelven objetos.[8] Estos objetos (generalmente listas) contienen todos los resultados calculados (estadísticos, p-valores, intervalos de confianza, residuos, valores ajustados, etc.). El usuario necesita aprender a extraer la información específica que necesita de estos objetos. La función summary() es un primer paso común, ya que formatea los resultados clave de muchos objetos de modelo (como los de lm y aov) de manera legible.12 Sin embargo, también es posible acceder a componentes específicos directamente usando el operador $ o corchetes [[ ]] (p.ej., resultado_t\(p.value, summary(modelo_lm)\)r.squared). Esta capacidad de tratar los resultados como datos en sí mismos es una característica poderosa de R, permitiendo la automatización de informes, la creación de gráficos personalizados basados en los resultados y la integración de los resultados en análisis posteriores, lo cual va más allá de las capacidades del visor de salida estándar de SPSS. Paquetes como broom (tidy(), glance(), augment()) son extremadamente útiles para convertir la salida de modelos estadísticos en data frames “ordenados” (tidy), facilitando aún más su manipulación y visualización.
7.7.8 Tabla: Mapeo de Procedimientos Inferenciales Comunes: SPSS vs. R (stats)
Prueba Estadística
SPSS Menú Path
R Paquete
R Función Principal
R Fórmula/Argumentos Clave
Prueba T una muestra
Analizar > Comparar medias > Prueba T para 1 muestra
stats
t.test()
t.test(x, mu =…)
Prueba T muestras indep.
Analizar > Comparar medias > Prueba T para m. indep.
stats
t.test()
t.test(y ~ x, data =…, var.equal = FALSE/TRUE)
Prueba T muestras relac.
Analizar > Comparar medias > Prueba T para m. relac.
chisq.test(table(var1, var2)) o xtabs(~var1+var2,…)
Correlación Bivariada (Pearson)
Analizar > Correlaciones > Bivariadas
stats
cor.test()
cor.test(x, y)
Regresión Lineal Simple
Analizar > Regresión > Lineales
stats
lm(), summary()
lm(y ~ x, data =…)
7.8 Navegando la Curva de Aprendizaje: Consejos para Usuarios de SPSS
La transición de la interfaz gráfica de SPSS al entorno basado en código de R presenta desafíos, pero son superables con el enfoque adecuado.
7.8.1 Abrazar el Código: Superar la “Fobia a la Sintaxis”:
El mayor obstáculo inicial para muchos usuarios de SPSS es el cambio a un flujo de trabajo basado en código.11 Es normal sentirse intimidado al principio.
Empezar Poco a Poco: No intente aprender todo R de golpe. Comience con tareas básicas como importar datos y calcular descriptivos. Modifique ejemplos de código existentes antes de escribir los suyos desde cero.
Enfocarse en los Beneficios: Recuerde las ventajas a largo plazo de usar código: reproducibilidad total, flexibilidad para análisis personalizados y mayor eficiencia una vez que se domina.[5]
Usar Herramientas de Ayuda: Herramientas de IA pueden ser útiles para generar fragmentos de código iniciales, explicar código existente o depurar errores simples, aunque siempre se debe verificar su salida.[75] RStudio también ofrece autocompletado de código y ayuda integrada.
7.8.2 Comprender las Estructuras de Datos de R:
A diferencia de SPSS que opera sobre un único dataset activo similar a una hoja de cálculo, R utiliza diversas estructuras de datos.11 Comprender las más comunes es esencial:
Vectores: Secuencias ordenadas de elementos del mismo tipo (numérico, carácter, lógico). Son los bloques de construcción fundamentales.
Factores: Vectores especiales para representar variables categóricas. Tienen niveles definidos (las categorías) y pueden ser ordenados o no. Es crucial no aplicar funciones numéricas directamente a factores sin convertirlos primero.[77]
Data Frames: Estructuras tabulares (filas y columnas) donde cada columna es un vector y todas las columnas deben tener la misma longitud. Es la estructura más similar al dataset de SPSS y la utilizada por tidyverse.
Listas: Colecciones genéricas que pueden contener diferentes tipos de objetos (vectores, data frames, otras listas, resultados de modelos, etc.). La salida de muchas funciones estadísticas en R es una lista. Errores comunes surgen al aplicar funciones a tipos de datos incorrectos.[75] Utilice class(objeto) para ver el tipo de un objeto y str(objeto) (structure) para obtener un resumen detallado de su contenido y tipos de datos internos.[17]
7.8.3 Encontrar y Usar Paquetes de R Eficazmente:
Los paquetes extienden la funcionalidad de R.
Instalación y Carga: Recordar install.packages(“nombre_paquete”) (una vez) y library(nombre_paquete) (en cada sesión).18
Documentación: Cada paquete viene con documentación. Use ?nombre_funcion para la ayuda de una función específica, help(package = “nombre_paquete”) para la ayuda general del paquete, y busque “vignettes”, que son tutoriales más largos incluidos en muchos paquetes. Conflictos: Ocasionalmente, dos paquetes diferentes pueden tener funciones con el mismo nombre. R advertirá sobre esto al cargar el segundo paquete (“The following object is masked…”). Para usar una función específica, use la sintaxis nombre_paquete::nombre_funcion().
7.8.4 Lidiar con Inconsistencias de Funciones/Sintaxis:
Dado que R ha evolucionado durante décadas con contribuciones de miles de personas, existen inconsistencias en los nombres de las funciones y la sintaxis entre R base y diferentes paquetes.[11]
Enfoque Consistente: Adoptar un conjunto coherente de herramientas, como el tidyverse (dplyr, ggplot2, readr, etc.), puede minimizar la exposición a estas inconsistencias para tareas comunes de manipulación y visualización de datos.
Leer la Ayuda: Siempre es buena práctica consultar la documentación (?funcion) para entender los argumentos específicos y el comportamiento esperado de una función antes de usarla.
7.8.5 Resolución de Problemas y Obtención de Ayuda:
Encontrará errores; aprender a resolverlos es parte del proceso. Ayuda Integrada: Use ?funcion, ?? “término de búsqueda” y help(package =…).3
Interpretar Mensajes de Error: Los mensajes de error de R pueden ser crípticos al principio, pero a menudo indican dónde ocurrió el problema (línea de código) y su naturaleza (p.ej., “object not found”, “non-numeric argument to binary operator”). Aprender a leerlos es clave.
**Recursos Online:* Stack Overflow, foros de la comunidad Posit, documentación de paquetes, blogs y tutoriales son esenciales.[3]
Preguntar Eficazmente: Para obtener ayuda online, es fundamental formular bien la pregunta. Esto a menudo implica crear un ejemplo mínimo reproducible (MRE o “reprex”): un pequeño fragmento de código autocontenido con datos de ejemplo (o una pequeña parte de sus datos) que demuestre el problema. Esto permite a otros entender y ejecutar su código para diagnosticar el error. El paquete reprex en R ayuda a formatear código, datos y salida para facilitar la creación de estos ejemplos. Aprender a crear un buen reprex es una habilidad crucial que acelera enormemente la obtención de ayuda útil de la comunidad R.
7.8.6 Obras revisadas y recomendadas para este capítulo
17.- [Using Functions in R Tutorial: A Comprehensive Guide - DataCamp, fecha de acceso: abril 16 2025] (https://www.datacamp.com/tutorial/functions-in-r-a-tutorial)
78.- [Moving from IBM® SPSS® to R and RStudio®: A Statistics …, fecha de acceso: abril 16, 2025] (https://www.amazon.com/Moving-IBM%C2%AE-SPSS%C2%AE-RStudio%C2%AE-Statistics/dp/1071817000)